Cloud specific features and optimizations, particularly geared toward AWS hardware. Also a combination of a 2 year release cadence and 5 years of Amazon backed of support for each release.
Yea, it is definitely a fake HTTP server which I acknowledge in the article [1]. However based on the size of the requests, and my observation of the number of packets per second in/out being symmetrical at the network interface level, I didn't have a concern about doubled responses.
Skipping the parsing of the HTTP requests definitely gives a performance boost, but for this comparison both sides got the same boost, so I didn't mind being less strict. Seastar's HTTP parser was being finicky, so I chose the easy route and just removed it from the equation.
For reference though, in my previous post[2] libreactor was able to hit 1.2M req/s while fully parsing the HTTP requests using picohttpparser[3]. But that is still a very simple and highly optimized implementation. FYI, from what I recall, when I played with disabling HTTP parsing in libreactor, I got a performance boost of about 5%.
> Yea, it is definitely a fake HTTP server which I acknowledge in the article
It's not actually an HTTP server though... For these purposes, it's essentially no more useful than netcat dumping out a preconfigured text file. Titling it "HTTP Performance showdown" is doubly bad here since there's no real-world (or even moderately synthetic) HTTP requests happening; you just always get the same static set of data for every request, regardless of what that request is. Call it whatever you like but that isn't HTTP. A key part of performance equation on the web is the difference in response time involved in returning different kinds (sizes and types) of responses.
A more compelling argument could be made for the improved performance you can get bypassing the Kernel's networking, but this article isn't it. What this article demonstrates is that in this one very narrow case where you want to always return the same static data, there's vast speed improvements to be had. This doesn't tell you anything useful about the performance in basically 100% of the cases of real-world use of the web, and its premise falls down when you consider that kernel interrupt speeds are unlikely to be the bottleneck in most servers, even caches.
I'd really love to see this adapted to do actual webserver work and see what the difference is. A good candidate might be an in-memory static cache server of some kind. It would require URL parsing to feed out resources but would better emulate an environment that might benefit from this kind of change and certainly would be a real-world situation that many companies are familiar with. Like it or not, URL parsing is part of the performance equation when you're talking HTTP.
Correct, it is a fake HTTP server, serving a real HTTP workload. This post is about comparing two different networking stacks (kernel vs DPDK) to see how they handle a specific (and extreme) HTTP workload. From the perspective of the networking stack, the networking hardware, and the AWS networking fabric between instances, these are real HTTP requests and responses.
> I'd really love to see this adapted to do actual webserver work and see what the difference is.
Take a look at my previous article[1]. It is still an extreme/synthetic benchmark, but libreactor was able to hit 1.2M req/s while fully parsing the HTTP requests using picohttpparser[3].
From what I recall, when I played with disabling HTTP parsing in libreactor, the performance improvement was only about 5%.
ScyllaDB uses Seastar as an engine and the DynamoDB compatible API use HTTP parsing, so this use case is real. Of course the DB has much more to do than this benchmark with a static http reply but Scylla also uses many more core in the server, thus it is close to real life. We do use the kernel's tcp stack, due to all of its features and also since we don't have capacity for a deeper analysis.
Some K/V workloads are affected by the networking stack and we recently seen issues if we chose not the ideal interrupt mode (multiqueue vs single queue in small machines)
Few questions if you will, it's an interesting work and I figure you're on ScyllaDB team?
1. Is 5s experiment with 1s warmup really a representative workload? How about running for several minutes or tens of minutes? Do you observe the same result?
2. How about 256 connections on 16 vCPUs creating contention against each other and therefore skewing the experiment results? Aren't they competing for the same resources against each other?
3. Are the experiment results reproducible on different machines (at first use the same and then similar SW+HW configurations)?
4. How many times is experiment (benchmark) repeated and what about the statistical significance of the observed results? How do you make sure to understand that what you're observing, and hence drawing a conclusion out of it in the end, is really what you thought you were measuring?
Am ScyllaDB but Marc did completely independent work.
The client vcpus don't matter that much, the experiment compares
the server side, the client shouldn't suck.
When we test ScyllaDB or other DBs, we run benchmarks for hours and days. This is just a stateless, static http daemon, so short timing is reasonable.
The whole intent is to make it a learning experience, if you wish to reproduce, try it yourself. It's aligned with past measurements of ours and also with former Linux optimizations by Marc.
I'm myself doing a lot of algorithmic design but I also enjoy designing e2e performance testing frameworks in order to confirm theories I or others had on a paper. The thing is that I fell too many times into a trap without realizing that the results I was observing weren't what I thought I was measuring. So what I was hoping for is to spark a discussion around the thoughts and methodologies other people from the field use and hopefully learn something new.
Very cool! Most of my bpftrace usage has been on the kernel side, but out of habit I often fall back to the debugger (or printf) in userland, which can seriously distort analysis of low latency functions, especially if polling or timers are involved.
Probably only for first year. Most TLDs are discounted significantly for the first year to get you in the door, then when you've built your business on the domain they hit you with the real fee when the renewal rolls around.
No, I confirmed that it is for all years. They deliberately don't make money on domain name registration. The use it to attract/retain business for their other services.
Sure, I was just pointing out that their current rates are cheaper than gandi, especially for renewals. So if someone wants to renew for multiple years it may make sense to switch.
I was wondering how they were going to manage the fact that AMDs Zen3 based instances would likely be faster than Graviton2. Color me impressed. AWS' pace of innovation is blistering.
I don't know. I prefer it when companies actually give the technical details.
> While we are still optimizing these instances, it is clear that the Graviton3 is going to deliver amazing performance. In comparison to the Graviton2, the Graviton3 will deliver up to 25% more compute performance and up to twice as much floating point & cryptographic performance. On the machine learning side, Graviton3 includes support for bfloat16 data and will be able to deliver up to 3x better performance.
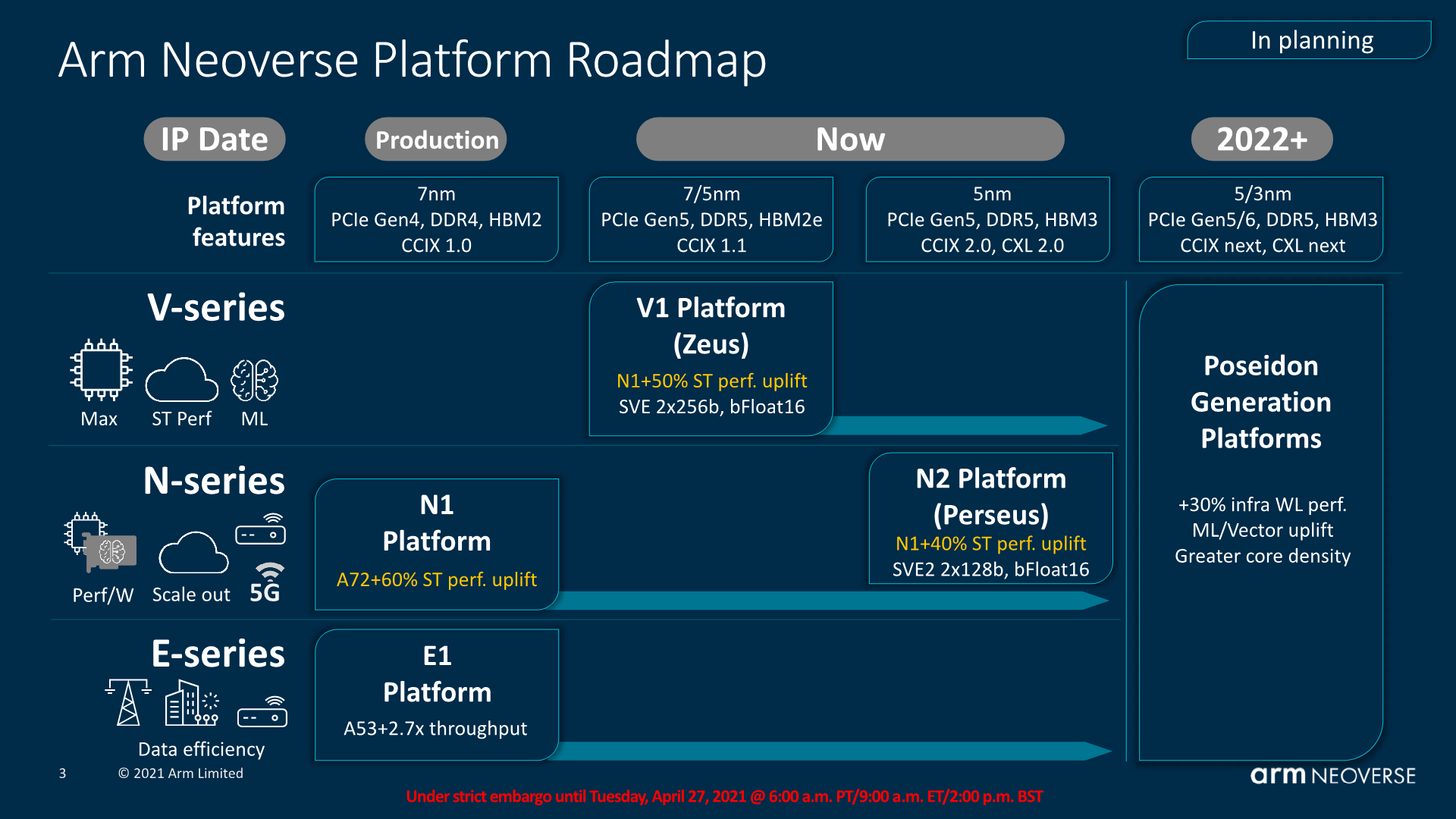
This means nothing to me. Why is there more floating point and cryptographic performance? Did Amazon change the Neoverse core? Is this N1 cores still? Did they tweak the L1 caches?
I don't think Amazon has the ability to change the core design unfortunately. This suggests to me that maybe Amazon is using N2 cores now?
But it'd be better if Amazon actually said what the core design changes are. Even just saying "updated to Neoverse N2" would go a long way to our collective understanding.
AWS re:Invent is this week. This was announced as part of the CEO's keynote. I am sure we will get more details throughout the week in some of the more technical sessions.
N2 does not use 256b SVE2, though its cousin Neoverse V1 does. I think there's a very real chance that Grav3 is actually V1, not N2. (N2 uses 128b SVE vectors, as does the Cortex-A710 it's based on.)
Aren't the Zen3 instances still faster than Graviton 3? DDR5 is interesting, and while lower power is nice, the customers don't benefit from that much, mostly AWS itself with its power bill. I haven't seen pricing yet, but assume AWS will price their own stuff lower to win customers and create further lock-in opportunities (and even take a loss like with Alexa).
I would guess price/performance matters more than peak performance for a lot of use cases. With prior Graviton releases, AWS has made it so they are better price/performance. Keep in mind that a vCPU on Graviton is a full core rather than SMT/Hyperthread (half a core).
> Aren't the Zen3 instances still faster than Graviton 3?
Irrelevant.
The vast majority of applications running in the cloud are business applications that struggle to saturate the CPU and waste most of the CPU cycles idlying by in epoll/select loops. Unless you need HPC, you do not need the fastest CPU, either.
> create further lock-in opportunities
Don't like AWS/Graviton? Take your workload to the Oracle cloud and run it on Oracle ARM.
Don't like ARM? If your app is interpreted/JIT'd (e.g. Python/NodeJs) or byte code compiled (JVM), lift and shift it to the IBM cloud and run it on a POWER cloud instance – as long as IBM offers a price-performance ratio comparable to that of AWS/Graviton or you are willing to pay for it.
On that note being able to rent a 160 core machine for $1.6/hour on Oracles cloud service is really impressive. If you have an integer intensive workload (i tested SAT solving) the Ampere A1 machine Oracle rents out are really competitive.
I think the idea is by attracting new customers to EC2 via performance/price, and then enticing them to integrate with other harder-to-leave AWS services
What's the motivation behind this question? Or why do you think Amazon wants to create lockin for Graviton processors.
Note that graviton represent a classic "disruptive technology" that is outside of the main stream market's "value network". I.e., it provides something that is valuable to marginal customers who are far from the primary revenue source of the larger market.
Yes, that's the problem. Graviton and M1 are competitive with x86. What about the rest of the ecosystem? Not so much. All the promising server projects have been canceled so far. You'll have to wait for Microsoft or Google to develop their own competitive ARM server CPU or migrate back to x86.
> Where is this narrative that Zen 3 instances are faster than Graviton 3 instances coming from?
Various benchmarks have shown EPYC Milan performing well compared to contemporary Xeon and ARM-based processors, but the most direct comparison that I've seen was when Phoronix compared Graviton2 M6g instances to GCP's EPYC Milan-powered T2D instances.[1] The T2D instances beat the equivalent M6g instances across the board, oftentimes by substantial margins.
Of course, that's comparing against Graviton2, not Graviton3, but the performance delta is wide enough that T2D instances will still probably be faster in most cases.
Unfortunately those claims don't translate to servers, because the IO die's power usage increased and perf/w isn't much better [1]. Do the math and you get around 14% gain in SPEC MT workloads.
Nice wording with 'per core performance'. We had difficulties properly conveying this point in our product when comparing our CI runners[1] to GitHub Actions CI Runner. I will be using it in our next website update. Tack
Honestly, they’re not innovating so much as forcing a product market fit that everyone knew existed, but didn’t have the business case to develop without a hyperscalar anchor customer (like AWS!)
If anything, this is just another data point that shows how truly commoditized tech is. I just worry what happens when Amazon decides to “differentiate” after they lock you in.
I've been rowing twice a day, every day since the pandemic and it has been a game changer. A high intensity 2k (while listening to music) in the mornings before I start my day, and a low intensity 5k (while watching tv) at night.
It is the most consistent I have ever been with at-home exercise and it has been perfect for managing stress and getting good sleep.
I sometimes watch an iPad (velcroed to the rowing machine) with standard bluetooth headphones. I don't find it too loud. You don't even need noise cancelling headphones unless you have a really loud machine.
Curious, what split are you going for your daily 2k? In college, I was doing semiregular 2k tests, and I could never imagine trying to uphold a regular schedule of them.
I don't go flat-out, but it is definitely high-intensity. I am always out of breath at the end, but not collapsed on the floor.
When I started I was doing around 2:05/500m. Now I am down to around 1:56/1:57, but some days I will go slower if I didn't sleep great or something. It is more about the consistency than the pace.
It is less than 8 mins total so it is enough to wake me up and get my heart pumping, but also allow me to recover quickly and feel ready to start the day.
{kind=link}